文章地址:https://dl.acm.org/doi/10.1145/3133956.3133982
标题:Practical Secure Aggregation for Privacy-Preserving Machine Learning
作者:Keith Bonawitz, Vladimir Ivanov, Ben Kreuter, Antonio Marcedone, H. Brendan McMahan, Sarvar Patel, Daniel Ramage, Aaron Segal, and Karn Seth
发表会议:CCS 2017
先梳理一下本文总的脉络吧
- Introduction
- Secure Aggregation for Federated Learnign
- Cryptographic Primitives
- Technical Intuition
- A Practical Secure Aggregation Protocol
- Security Analysis
- Evaluation
- Discussion and Future Work
介绍

开局先来个图,大概看一下就行。
本文的主要内容就是提出了 Secure Aggregation,后文就叫安全求和吧,用在联邦学习场景下从多个客户端场景下 parameter server 对每个客户端的梯度进行汇聚。所以问题定义为:
有 $m$ 个客户端$C_1, C_2, …, C_m$,其中每个客户端 $C_i$拥有私密数据$x_i$。而业务需求需要所有的客户端联合起来,共同求出私密的和 $\sum_{i=1}^m x_i$给服务端,同时要满足安全型需求,即不能向服务端和其他客户端泄露数据 $x_i$。
应用场景上,本文主要选择了手机作为客户端这个比较有代表性的FL场景,在这个场景下有两个核心问题:
- Communication:最好不要占用太多的流量、带宽之类的东西;
- Drop out: 用户的手机不可控,经常会有客户端掉线。
所以本文提出了两种模型:
- plain model: 效率高,可以抵御 HBC 攻击者;
- random oracle model: 可以更加保护隐私,可以抵御 active adversaryrial server。
联邦学习下的Secure Aggregation
此章节大概讲了一下 FL 场景下为啥要有 Secure Aggregation 这个东西,讲了一下当前所谓的“痛点”。毕竟是谷歌,这些痛点都是现实应用中实实在在碰到的,可不是普通论文中描述的理论情况下的不足。总的来说就是在联邦学习场景下,一个好的安全聚合应该要满足以下几点:
- 可以处理高维向量
- communication-efficient
- robust to users dropping out
- 具备较强的安全特性(对于server,或未授权的网络模型)
密码学基础知识
这里主要涉及以下几个概念,后面一个个介绍,有些东西不知道怎么翻译成中文,就直接用的英文,其实也很好懂。
- 秘密分享
- Key Agreement
- Authenticated Encryption
- 伪随机数生成器
- 数字签名机制
- 公钥基础设施PKI
秘密分享
这个东西算是密码学的相关概念,可以叫秘密分享,当这个秘密是秘钥的时候也可以叫做秘钥分享。它的功能是把一个秘密 $s$ 分给 $n$ 个用户,然后这 $n$ 个用户当中任意 $t$ 个用户即可恢复秘密 $s$。我们假定用户集是 $\mathcal{U}$。所以秘密分享包含两个部分:
- 分发阶段:$\textbf{SS.share}(s,t,\mathcal{U})\rightarrow \{(u, s_u)\}_{u\in \mathcal{U}}$,表示把秘密 $s$ 分享给所有的用户,每个人的数据是秘密份额 $s_u$;
- 重建阶段:$\textbf{SS.recon}(\{(u, s_u)\}_{u\in\mathcal{V}}, t) \rightarrow s$,表示给定一系列用户和秘密份额以及阈值 $t$,就可以重建秘密 $s$。
Key Aggrement
秘钥协商包含以下一些操作:$\textbf{KA.param, KA.gen, KA.agree}$,其中,$\textbf{KA.param}(k) \rightarrow pp$ 产生公共参数,然后 $\textbf{KA.gen}(pp)\rightarrow (s_{u}^{SK},s_{u}^{PK})$ 允许任何一个用户用来产生公私钥,然后$\textbf{KA.agree}(s_{u}^{SK},s_{v}^{PK}) \rightarrow s_{u,v}$ 表示用户 $u$ 可以结合自己的私钥和对方的公钥得到一个 $u$ 和 $v$ 之间的 $s_{u,v}$ 秘密。
本文采用的是 Diffie-Hellman 秘钥交换协议,其中三个操作分别是:
- $\textbf { KA.param }(k) \rightarrow\left(\mathbb{G}^{\prime}, g, q, H\right)$,生成素数 $q$ 的 group $\mathbb{G}^{\prime}$,生成元为 $g$, 同时给定一个哈希函数 $H$;
- $\textbf { KA.gen }\left(\mathbb{G}^{\prime}, g, q, H\right) \rightarrow\left(x, g^{x}\right)$,选取 $x \leftarrow \mathbb{Z}_{q}$ 作为私钥 $s_{u}^{SK}$,$g^x$ 作为公钥 $s_u^{PK}$
- $\textbf { KA.agree }\left(x_{u}, g^{x_{v}}\right) \rightarrow s_{u, v}$,计算 $s_{u, v}=H\left(\left(g^{x_{v}}\right)^{x_{u}}\right)$。
所以经过上面三个操作之后,共享数据的两方可以得到只有他俩知道的随机数 $s_{u,v} = s_{v,u}$,其利用的原理就是 $(g^{x_u})^{x_v} = (g^{x_v})^{x_u}$,然后再套一个哈希函数。
Authenticated Encryption
Authenticated Encryption 在两方传输消息的过程中可以保证机密性和完整性。它包括三个操作:
- 秘钥生成算法,生成一个秘钥 $c$;
- $\textbf{AE.enc}(c,x)$,利用秘钥对数据 $x$ 进行加密,得到密文,假定密文是 $y$ 吧;
- $\textbf{AE.dec}(c, y)$,对密文揭秘,可以解密就输出铭文,否则输出错误标志 $\perp$。
所以如果正确的话,就有 $\textbf{AE.dec}(c, \textbf{AE.enc}(c, x))=x$,即解密成功了
伪随机数生成器
伪随机数生成器,缩写叫 PRG,也有写论文叫做 PRNG,即 Pseudorandom Number Generator。在这篇文论文中,这么理解 PRG 就可以了,给定一个随机数种子,PRG 可以基于这个种子生成一个或多个新的随机数,虽然是靠公式生成的,但是人是找不出规律的。所以才叫“伪”随机数。
签名机制
签名机制包含三个操作,分别是:
- $\textbf { SIG.gen }(k) \rightarrow\left(d^{P K}, d^{S K}\right)$,表示生成公私钥对;
- $\textbf{SIG.sign}\left(d^{S K}, m\right) \rightarrow \sigma$,表示利用私钥对消息 $m$ 进行签名;
- $\textbf{SIG.ver}{}\left(d^{P K}, m, \sigma\right) \rightarrow\{0,1\}$,通过公钥对签名进行验证,并与源数据 $m$ 进行对比确定验证是否通过。
公钥基础设施
PKI 是用来实现基于公钥密码体制的秘钥和证书的产生、管理、存储、分发和撤销等功能的集合。这样各种基于秘钥的算法就能很容易地运行了。
技术出发点
想一下我们开头的问题定义,就是有 $n$ 个用户,每个用户有一个值 $x_u$,然后 server 需要计算 $\sum x_u$,但是每个用户又不能把自己的数据交出去。于是,作者提供了这么一个思路,能不能用户1减去个数,用户2来加个数,这样用户1和用户2的数据都不准了,但是总的求和还是准的。然后这个思路扩展一下,就有了论文中的方案。
Masking with One-Time Pads
所有的用户两两协商一个随机数,即:用户 $i$ 与用户 $j$ 协商随机数 $s_{i,j}$,然后对数据 $x_i$ 按照下式进行扰动,结果为 $y_i$:
当然,在FL场景中,上面的 $x$ 和 $s$ 实际上都是多维向量。为了说明问题方便,下面就不以向量的形式说明了。然后显然就可以证明:$\sum y_i = \sum x_i$ 。所以服务器就计算:
举个例子,假如有三个数据 $x_1, x_2, x_3$,那么加掩码的过程为:
有个图方便后面说明问题,就是:
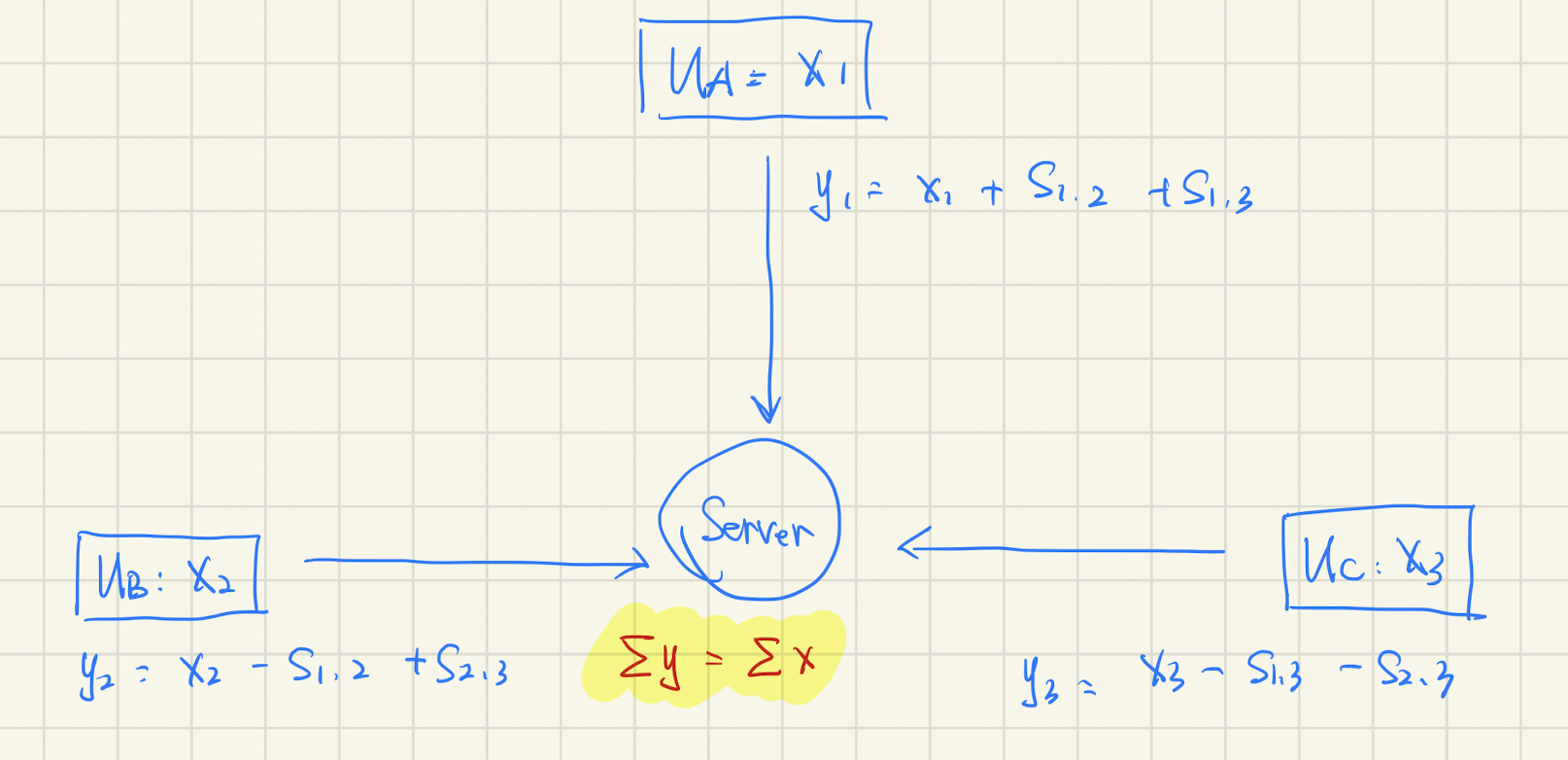
所以,就是每个随机数被减了一次,又被加了一次。因此有:
这个逻辑看上去挺完美了,但是还没有解决,面临以下几个问题:
- 随机数怎么协商
- 要是某个客户端突然掉线了咋办
如何协商随机数
现在的算法是两两如何确定一个随机数并且这个随机数还不能被第三者知道。这个方案可以使用DH秘钥协商方案来实现,并且可以借助 pseudorandom generator(PRG) 减少通信开销。协商的秘钥作为伪随机数生成器 PRG 的种子。所以协商随机数,实际上协商的是随机数的种子。
客户端掉线/延迟怎么办
上面的步骤好像可以解决 Secure Aggregation 的问题了,但是会产生一个新的问题,要是某个客户端“掉线”了,咋办?
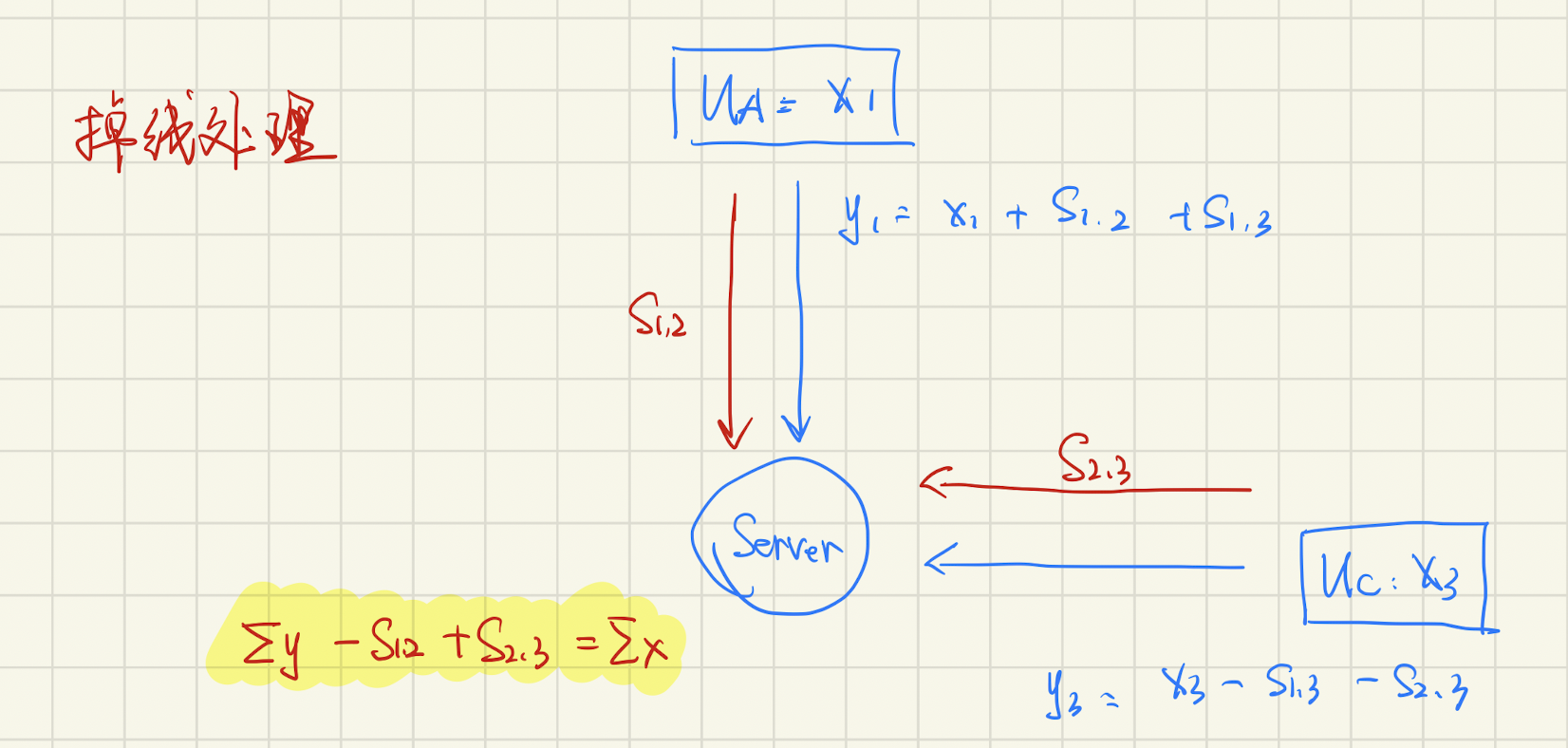
我们不妨假设第二个客户端掉线了,那么现在的需求实际上就是求 $y_1 + y_3$ 了,所以Server可以去问第1、3个客户端要到 $s_{1,2},s_{2,3}$,这样子算下面这个公式就可以了:
目前好像掉线的时候没啥问题。但是想想,要是恢复阶段又有客户端掉线了,咋办?所以我们需要只要存在足够的客户端,这些随机数就能被还原回来的方法。从理解上来看的话,我么可以认为每个客户把 $s_{u,v}$ 采用秘密共享的方式分发出去了,并且只要有 $t$ 个客户端在线,就可以还原回 $s_{u,v}$。(实际上,分发的是公钥的share,然后根据公钥和$v$ 的数据,可以算出来 $s_{u,v}$)。有了这个 $t$-out-of-$n$ 的秘钥共享方案,只要有 $t$ 个用户在线,就不怕客户端掉线了。
但是等等,要是不是掉线,而是因为延迟,这时候 $y_2$ 突然来了怎么办?
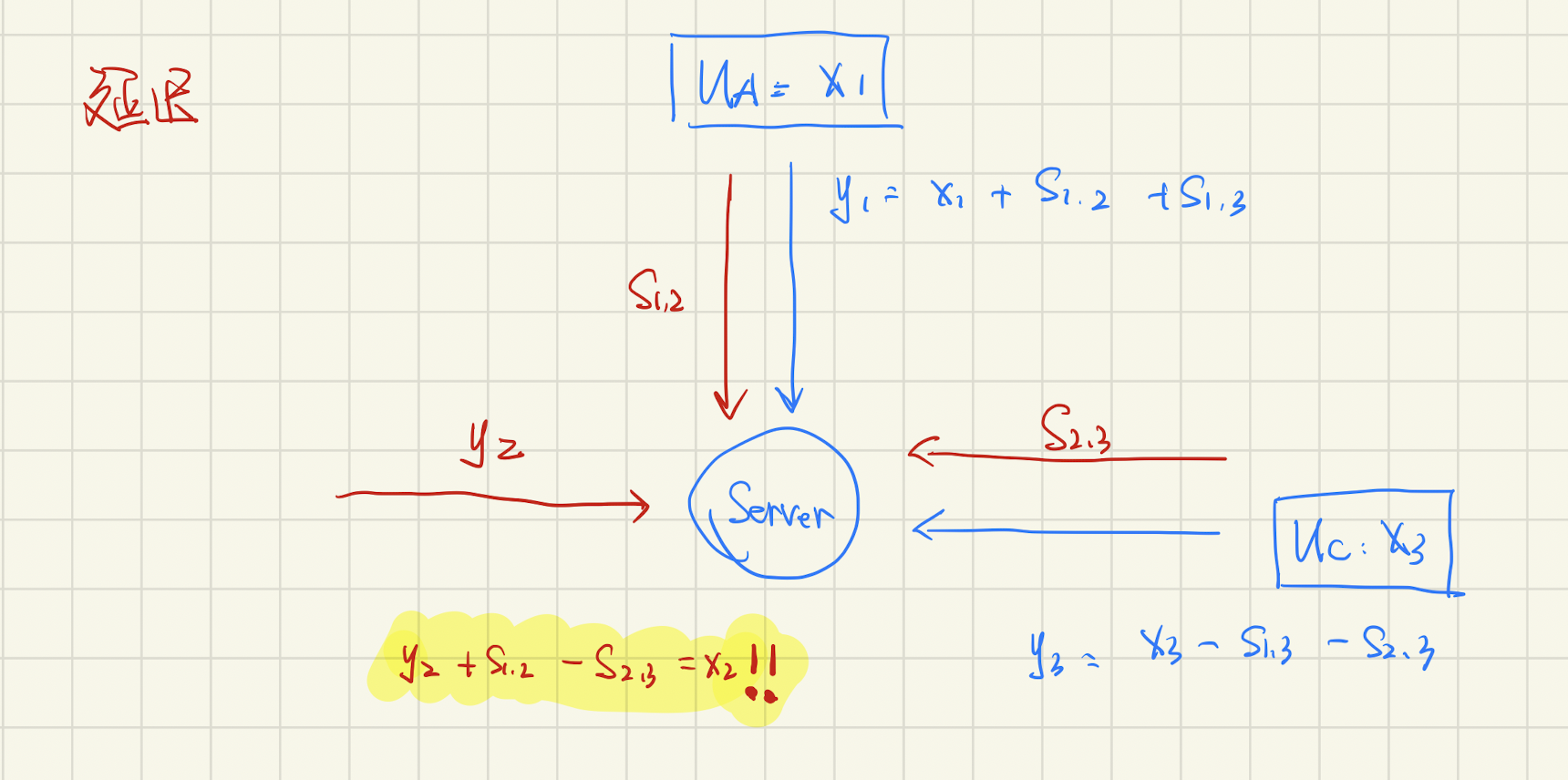
这时候,我们就可以根据 $y_2 + s_{1,2}-s_{2,3}$ 算出来 $x_2$ 了,原始数据都还原出来了。大忌。所以我们不仅要能恢复出因用户掉线/延迟下回复随机数 $s$,还得确保不能恢复数据 $x$ 。
Double-Masking
所以作者尝试,引入一个新的随机数 $b$,把这个随机数和数据绑定,就是这样:
PRG 可以不那么细究,直接理解为 $y_u = x_u + b_u + \sum_{ u < v } s_{u,v} - \sum_{u > v} s_{u,v}$ 即可。然后采用以下的策略:
- 在分发阶段,随机数 $b$ 和 $s$ 均采用秘密分享的方案分发出去,并且保证 $t$ 个用户就可以恢复。
- 在恢复阶段,对于一个诚实的用户 $v$,他不会把 $b_u$ 和 $s_{u,v}$ 同时说出去。如果用户 $u$ 掉线了,那么 $v$ 会说出 $s_{u,v}$,如果用户 $u$ 在线,那么 $v$ 会说出 $b_u$。
当然,上面所谓的说出 $b_u$ 实际上是说出 $b_u$ 的 share,要至少 $t$ 个 share 才能恢复出 $b_u$。因为采用了两类随机数,所以这个方法也叫做 Double-Masking。也就是说,在大家都不掉线的情况下,反正 $b$ 是可以恢复出来的,双掩码方案就相当于单掩码方案了。在有用户 $u$ 掉线的情况下,数据 $x_u$ 也就不拿来就和了,所以 $b_u$ 就不用去管它,恢复 $s_{u,v}$ 就好了。
总的流程
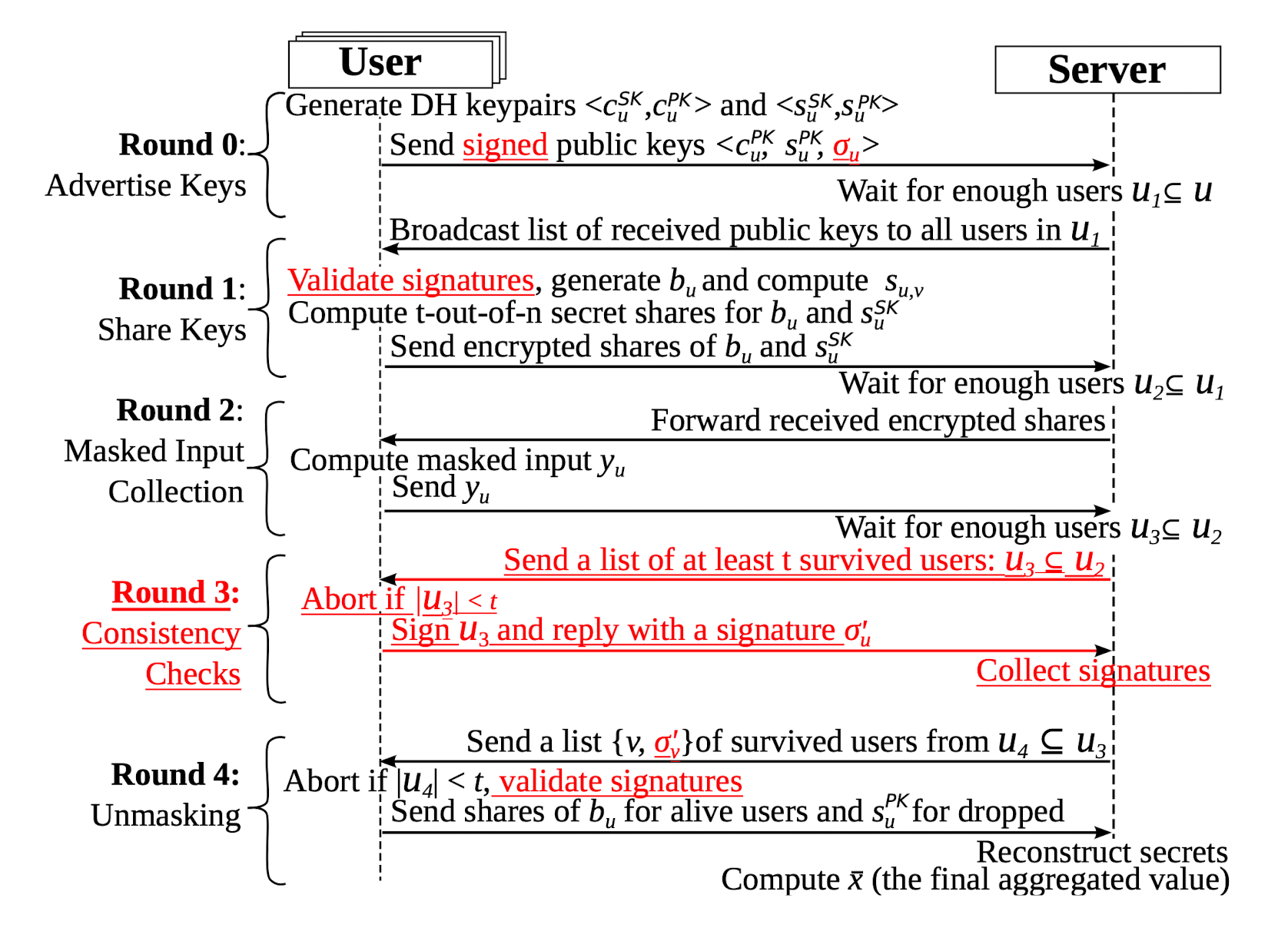
结合密码学基础知识和论文涉及的 Masking 机制,总的流程就如上图所示了。其中,红色是用于应对 active-adversary 的方案,对于 HBC 安全模型可以不考虑。实际上,理解了Masking 的方法之后可以根据自己的需求去设计对应的机制,所以这个机制也不用如此地去深究。
然后作者列举了不同阶段 User 侧和 Server 侧的计算、通信、存储代价,其中用户数量为 $n$,每个用户的数据维度是 $m$,各种cost如下表所示:

其他章节
个人感觉这篇论文的核心到这里就已经掌握了,后文的包括这个协议的进一步细化、安全性描述、实验结果、相关工作等,这里就不继续做笔记去一步一步详细地记录了。如果以后再接触相关内容发现这里有坑,再来补一下。
本篇内容到这里就结束了,欢迎关注公众号《差分隐私》,获取更多前沿技术。


